テキストマイニングとは
「テキストマイニング」と言う言葉が、語られ始めたのは1996年頃である。当初は、データマイニングの一分野とする見方が強かったが、現在は、独立した技術分野として捉えられており、その基本的な相違は以下の通りである。
a)文書情報の分類に一定の法則はなく、個別の判断が求められる。このため、数値情報の様な統計的評価による自動処理は困難であり、テキスト特有の分析手法が必要となる。
b)元々文書情報は多義性を持つために、多様な分類が可能である。分析者は多くの可能性の中から、特定の分類方針を策定し、それに基づいて分類条件を設定してゆく必要がある。
以上より、テキストマイニングとは、分析者がコンピュータの支援を受けて、大量のテキスト情報を整理・分類するものであり、分析ツールは上記の知的作業を、如何にスムーズ゙に支援できるかがポイントとなっている。
また、テキストマイニングはVOC(Voice Of Customer:顧客の声)活動と共に進化を遂げてきた歴史があり、「顧客の囲い込み戦略」の比重が増す経済環境の中で、「顧客の声」を直接分析する技術として、市場拡大と技術進化の途上にある。
目次
- テキストマイニングの始まりと展開

- テキストマイニングの基本:「カウントすべきは、単語ではなく文である」
- テキストマイニングのパワー
- テキストマイニングが実現すべきもの
- テキストマイニングは知的能力の倍力装置
テキストマイニングの始まりと展開
弊社のテキストマイニング技術の開発活動は、1996年にスタートした。当時の状況を例えてみれば、広大な未開の荒野に何のツールも持たずに、乗込んで行った様なものだった。確かに、テキストマイニングと言う言葉は存在していたが、それは過去50年の歴史をもつデータマイニングに対比して名付けられただけで、その中身は全くの白紙であり、ゼロから作り出すしかなかった。フロンティアとしての可能性に満ちてはいたが、未知の課題が次々と出現し、様々な苦難の連続であった。
その一例を挙げれば、まずハードウェアが問題であった。テキストデータの処理には広いメモリ空間が必要であるにもかかわらず、当時のマシンスペックは極めて不十分なものであった。当時の業界では、SUNのサーバ機が群を抜くトップ性能であったが、何とそのメインメモリ容量は256KBに過ぎなかった。今振り返れば、笑ってしまう様なメモリ容量であるが、それが最新鋭機となれば、アプリはそこで稼動する様に、様々な工夫を重ねねばならなかった。そして、いよいよ客先デモとなると、まず運搬する車を手配した上で、3段重ねのSUNサーバを持ち込んでデモすると言う珍道中を、繰り返していたものであった。
業界に先駆けて開発されたVextMinerは、幸運にも電通、キヤノン、富士フイルム等のトップ企業に採用され、その現場部門からの様々な要望&苦情を積極的に取り入れる事で、大きな進化・発展を遂げる事が出来た。2000年当時では、数万件のテキストデータを処理するだけでも数時間を要していた分析システムが、今では数百万件を十数分でカテゴライズする事も可能となっただけでなく、予兆発見を初めとする様々な分析機能が「大量データに潜む新たな発見」の発掘を支援してくれるまでに至っている。
テキストマイニングの基本:「カウントすべきは、単語ではなく文である」
上述の状況は、拙著「テキストマイニング活用法(2002年11月)」で発表し、業界での先鞭としてテキストマイニング技術の有効性を示す事ができたが、その後の10年間は、本質的な議論がなされないまま時間だけが過ぎてしまい、現状での業界はあるべき方向を見失っている感がある。
今では、フリーソフトを含めると20種類以上の分析ツールが、市場に出回っているが、期待に反したつまらない結果に、失望した方々も多いのではなかっただろうか?多くのツールが分析結果として提示する「単語の頻度」や「単語間の相関」を見させられて、「判った様な、判らない様な・・・」モヤモヤとした感覚を持った人は、正常な判断力の持ち主である。
この様な分析結果は、「得るべき目標を目指したものなのだろうか?」と言う素朴な疑問が生まれても当然である。そもそも、我々が目視でテキスト情報を整理する場合に、単語の頻度を数えるだろうか? そんな人は、まずいない。誰もが行なう方法はただ一つ、「丹念に読んで、同じ内容のテキストを一つ一つカウントする事」である。
そこで、「単語をカウントして、何が判るのか?」を素直に問うべきなのだと我々は主張したい。だが、実際に問いかけてみても、意味のある回答が返って来たためしはない。単に、「それが、テキストマイニングの基本ですから・・・・・・。」と言うばかりである。一体誰が決めた基本なのか? 技術が未成熟なために、これしかできないと自ら告白している様なものであり、これでは信頼に足る技術としての要件を全く満たしていない。
この様な未熟なアプローチとは異なり、弊社では開発当初から「カウントすべきは単語ではなく、文である事」を主張し、様々な分析機能を開発すると共にそれらをテキストマイニングの方法論として体系化してきた。では、「何故文単位の分析が必要で、単語にバラしてはいけない」のだろうか?詳しい解説は「技術解説」に譲るが、その必要性は簡明である。
何故なら、「文は単語により構成されているが、その文意は単語の序列や配置により醸し出されるものであり、バラバラにしてしまうと失われてしまうものである。」からだ。ちょうど、DNAがたった4種の塩基から構成されているだけなのに、その配列が極めて複雑な機能を内在しているのと同じである。誰も、塩基の数が特徴を表すとは、考えないだろう。そして、音楽も同様だ。曲を音素に分解してしまうと、その美しいメロディは消えてしまう様に、世の中には分解してはならないものが沢山あるにもかかわらず、要素に分解する事が分析と考えるのは、余りに単純かつ本質を見失ったものと言わざるを得ない。
まさに、「言葉は、互いに他の言葉との関係でしか定義されない。」(石川 博久:思考・表現・コンピュータ)のである。
テキストマイニングのパワー
テキストマイニングは、分類作業を通じて様々な経営課題の発見を、スピーディに支援するものであるが、このパワーは絶大である。弊社は既に1000社以上のデータを分析した実績を有しているが、数万件程度のデータの分析~レポート作成に要する時間は、極めて短い。(実はデータ量が増えても、作業時間は余り変わらない。変化するのは、話題のバリエーションの多さによる。)しかも、こうした短時間の分析であっても、誰も知らないか、もしくは極一部の当事者しか知らない事実を容易に抽出して、関係者を驚嘆させる事ができるのだ。
ある製造業で、分析結果をプレゼンした時の話である。居並ぶ経営トップの前で、VOC(Voice of Customer)の分析結果を報告した。顧客からの問合せ~苦情に至る主要意見を分析すると共に特徴的な少数意見を報告する中で、ある指摘をした。「数は多くはないが、1年前に対策した不具合が再発している。急増しており対策が必要ではないか?」同席していた担当役員は、このトラブル対応の渦中にあったため、余りの指摘に絶句してしまった。
こうした例は数多いが、いずれも評価されるのが作業時間の短さである。通常、作業時間と得られる成果は比例関係にあるが、VextMinerでは圧倒的なスピードで分析が可能となる。2000年当時に、ある大手広告企業とで実験した例では、2000件のデ-タを人手で分析した際には2週間(実働10日)を要したが、テキストマイニングを用いて同等の分析をすると3Hで完了した実績がある。勿論、人手では読む事の出来ない数万件以上のデータとなると比較しても意味がないだろう。
実は、このスピードがもたらすものが、分類結果の精緻化である。手作業では疲れ果ててしまう仕分け作業を即時実行してくれるため、様々な試行錯誤を短時間で行って最適解を見つける事が容易になった。それにより、分析結果のレベルが飛躍的に向上し、前述の様な結果を生み出す事が出来る様になったのである。
テキストマイニングが実現すべきもの
テキストマイニングは、大量のテキスト情報を処理するものであるが、これをハンドリングする能力を、筆者らはマイニングスキルと呼んでいる。即ち、コンピュータの支援を受けながら大量情報の分析を行う能力を指しているが、その目標は「分析システムと人とのコラボレーションによる新たな知の発掘」にある。分析システム(=テキストマイニングツール)と分析者の両者がシームレスに協業する事で、未知の知識を発見するための試行錯誤を、効率的に行う事を目指している。勿論、こうした支援を行なうためには、システムが提示する分析結果が判りやすく提示されて、様々な連想がパッと想起される必要がある。
「分析者が見てすぐに内容が判る」⇒「「気付き」が生まれる」⇒「新発見の糸口が見える」
繰返すが、この様な効果を実現するには、「文単位の分析」が必須となる事が、理解頂けるだろう。
しかしながら、如何にハイレベルな支援をシステムが行ったとしても、最終的に「新たな課題」を発見するのは人であり、玉石混合の分析結果から宝を見抜く眼力が必要である事に何ら変わりはない。マイニングスキルとは、「業務への洞察力」と「分析ツールを駆使する力」の2つから構成されるものであるが、これをどの様にしてレベルアップしてゆくのかが、これからの大きな課題となっている。テキストマイニングでは、改善すべき課題や問題点を発見するきっかけとなるものを「気付き」と呼んでいるが、僅かな兆候に対し「何かおかしい・・・」と感じ取るセンスを磨く事が望まれているのである。
即ち、人間側がパワフルな分析力を持って、“より多く”かつ“より深い”新発見を行なえる様に支援するのが、テキストマイニングの理念なのである。文字の発明以来長い間、人間の思考活動は個人の頭脳内に留まってきた。約半世紀前に始まったコンピュータの普及は、数値情報の解析をベースに展開してきたが、直近の10年間で、ようやく「数値からテキストへ」の発展が開始されてきたのである。元々テキスト情報とは、「論理の世界」から「おしゃべりの世界」までの幅広い人間の知的活動を表現するものであり、数値情報にはない「曖昧さ」や「多義性」を含む豊潤で奥深い情報である。こうした重層的なテキスト情報を、多面的かつスピーディに分析する事で、我々自身が「より創造的に」なり、コンピュータの支援を得て「知的能力をパワーアップ」するのが、テキストマイニングの目指すものなのである。
テキストマイニングは知的能力の倍力装置
これまでに述べた様に、テキストマイニングは分類作業を通じて「理解する」プロセスを支援するものであるが、その理念についてまとめておきたい。
世の中には様々な倍力装置が存在する。判り易いのは、建設機械の様に物理的なパワーアシストを行なうもの、あるいは望遠鏡の様に視力を向上するものだ。だが、知的能力についてはどうだろうか?冒頭に述べた様に、知的作業である「知る」を支援するものがWebにおける検索技術であり、本題である「理解する」を支援するものがテキストマイニング技術である。
本書で紹介するテキストマイニング技術の詳細は後述するが、その基本コンセプトは「人とシステムとのコラボレーション」である。つまり、如何なる分析者もシステムの支援なしに、大量文書を処理する事はできないし、同時に如何なるシステムも分析者の意図なしに、価値ある分析結果を生み出す事はできない。従って、重要なのは、この両者をどうやって効率的かつクリエイティブに協業させるか?であり、その答えが「コラボレーションによるテキストマイニング」という基本コンセプトであった。(図1)
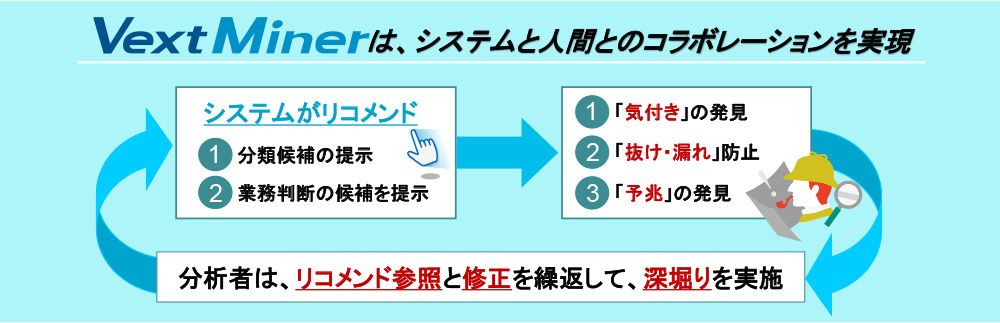
図1、テキストマイニングの基本コンセプト
建設機械は作業者の指示通りにしか動かないと言う「マスター・スレイブ方式」であるが、テキストマイニングは違う。システムが提示する自動分類結果を、分析者が見て新たな気付きを発想し、さらに詳細な分析へとスパイラルアップするものである。つまり、「マスター・スレイブ」から一歩進んだ「人とシステムとがお互いの長所を協調させる手法」なのである。

