テキストマイニング基本技術の解説
テキストマイニングツール:VextMinerの世界にようこそ!
テキストマイニングの基本は、「大量のテキスト情報を、どうやって整理&分類して、素早くまとめるのか?」に尽きます。情報の整理には、大多数の類似意見と少数意見を区分してまとめてゆく必要がありますが、こうした分析プロセスをスムーズに支援するのが、VextMinerです。
初見のデータを分析する場合でも、クラスタリングにより分類候補を自動抽出し、その結果を分析者の意図に沿って画面上で編集する事で、目指す分類結果を素早く生成できます。また、目視では発見困難な少数意見(予兆)に対しても、全件マッチングにより少数意見をヌケモレなく抽出する事で、システマチックに「気付き」を見付けられる仕掛けを用意しています。
本解説では、各分析プロセスとその機能について詳しく記述してありますが、大事なのは次の分析フローの考え方(=テキスト分析の方法論)を理解する事です。
「全体像を素早く把握」⇒「分類体系構築(分類ルール設定)」⇒「クロス分析」⇒「予兆発見&深堀り」
上記フローを理解し、それに沿った分析を行う事で、VextMinerが提供するビジュアルなインターフェースとパワフルな分析機能を実感頂けると思います。
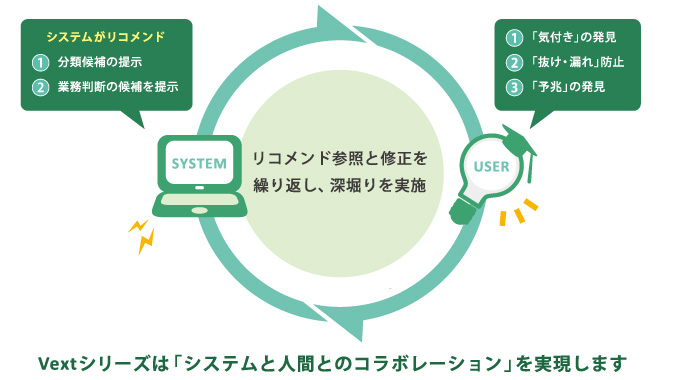
VextMinerの基本コンセプトは、「システムと分析者がコラボレーションしながら、スピーディに分析作業を行う事」ですが、これは誰にとっても経験のない全く新しい世界です。初めは戸惑う場面もあるかと思いますが、決して難しい世界ではありません。統計解析の様な専門知識は不要ですが、自転車に乗る時の様に「ツールに慣れる」&「身体で覚える」事がポイントです。ツールと一体となって、様々な課題を乗越えて行く経験を通じて、初めてツールを乗りこなして行くコツを体得できるのです。
「膨大な情報を持っているが、宝の持ち腐れになっている」「分析だけでなく、結果を実務に生かしたい」と考える人のための支援ツール、それがVextMinerです。
目次
1. テキストマイニングについて
- 1) テキストマイニングの概要
- ・テキスト分析手法の区分
- ・文単位で分析するメリット
- 2) テキストマイニングでの課題と対応方策
- ・テキスト分析での課題と対応策
- ・分析作業での3大課題(A,B,C)と手法の比較
- ・VextMinerの特長(まとめ)
2. テキストマイニングの基本技術
- 1) 自動学習機能(森を見る技術)とは?
- 2) クラスタマップ機能(意図の反映)
- 3) カテゴライズ機能(分類ルールの設定)
- 4) 全件マッチング機能(少数意見の発掘)
- 5) 予兆の発見→監視へ
- 6) 分析フローをトータルで支援

