【ACL2021の3つポイント】自然言語処理のトップ会議 ACL-IJCNLP2021に参加してきました。

なかなか馴染みのない言葉が盛りだくさんですが、Google先生を駆使して立ち向かってみてください!

残暑が続きますね。「ACL2021」でグーグル検索すると、まず出てくるのがサッカーのAFC Champions Leagueですが、我々テキストマイニング界隈を生業にするものにとっては、ACL2021と聞くと、自然言語処理(Natural Language Processing)のトップの国際会議の方を思い浮かべます。
本記事では今年2021年8月1日~7日に開催されたACL-IJCNLP 2021での3つのポイントをご紹介いたします。
3つのポイント
(1) 完全リモートセッション
(2) 深層学習―事前学習モデルの隆盛
(3) 機械翻訳に最適な語彙の発見―VOLT(Vocabulary Learning via Optimal Transport for Neural Machine Translation)
(1) 完全リモートセッション
ACL2021は、もともとタイのバンコクで開催される予定でしたが、Covid-19の感染予防対策のため、今年もACL2020同様、完全リモート形式での開催となりました。
ACL2019はイタリアのフィレンツェでオンサイト参加費$700でしたが、ACL2021は$175でした。参加費なんと75% offで、ほぼ全てのセッションが録画され後からも視聴できるので、国際学会も最適解に近づいているように思います。
会議のプラットフォームとしては全セッションはUnderline.ioのもとで進行され、リアルタイムセッションはZOOM、ポスターセッションはgather.townというツールを利用する形式でした。ZOOM以外は日本国内のビジネスの場ではあまり利用されていないように思いますが、どちらも非常に便利なツールです。
特にgather.townは仮想空間をゲーム(ドラゴンクエスト)のように行き来しながら参加者とコミュニケーションを図れるツールで、リモートワークでも活用のシーンが広まっていきそうです。
(2) 深層学習―事前学習モデルの隆盛
オープニングトークでは、ACL2018とACL2021での論文テーマを比較するという試みがなされましたが、RoBERTa/Adapters/BART/GPT2/XLM-Rといった新たなtransformerベースの事前学習モデルを扱うものや、これらのモデルを解釈する論文が多数採択されていました。これは、2018年10月にGoogleから発表され世界を震撼させたBERTの派生系と呼ばれるものたちです。
今から約三年前の2018年11月、私は機会があってACL主催のEMNLP2018(ベルギー・ブリュッセル開催)にベクスト社員として参加することができました。
EMNLPはACL同様に自然言語処理のトップカンファレンスです。
BERT発表の直後でしたが、多数のセッションでBERTに関して専門家の議論を直接聞くことができ、領域を跨いだブレークスルーが起きた瞬間に一次情報に触れられたことに興奮を覚えました。
当初はまだ、Allen Institute for AIがELMoを普及させるべく宣伝活動をしており、セサミストリートのELMOのぬいぐるみがEMNLP参加者のノベルティとして配布されました。
私の3歳の娘はこのELMO人形の影響でセサミストリートにのめり込みましたが、自然言語処理界隈では、ELMoは登場後すぐにBERTに駆逐されてしまいました。
そして、2021年は更にTransformer自体のアーキテクチャの最適化が行われ高速・軽量・高精度を実現するものが登場したり、自然言語処理の領域を超えてDNA解析や画像認識、音声認識においてもTransformerが活躍しています。
(「???」となってしまった方、正常な反応ですのでご安心ください!)
BERTの基本要素であるTransformerで用いられているdot product attentionをfull-attentionからglobal-attentionにすることで、入力長を512トークンから2048トークン以上まで扱うことができるようにしたBigBird(これもセサミストリートのキャラの一つです)は、遺伝子解析(genetics analysis)においても有用性が確認されています。また、画像認識(Computer Vision)では、Vision Transforme(ViT)がベンチマークにおけるSoTA(State of The Art)水準の記録を叩き出したり、音声認識(Automatic Speech Recognition)ではGoogleが提案したConformerが大幅にSoTAを塗り替えるなど、自然言語処理の領域を超えてTransformerというアーキテクチャの優位性が示されています。
しかしながらも、昨今はMLP MixerやgMLPなど多層パーセプトロンを拡張したtransformerよりもシンプルなアーキテクチャでSoTA水準の精度を達成できるようになっていたり、GNN(グラフニューラルネットワーク)で、Transformerを表現できることがわかっていたりと、まだまだ深層学習の事前学習モデルでの最適なアーキテクチャを探る冒険は続きそうです。
(3) 機械翻訳に最適な語彙の発見―VOLT(Vocabulary Learning via Optimal Transport for Neural Machine Translation)
今年のACLのBest Paper Award(最優秀論文賞)は、TikTokで有名なByteDanceのAI Labが発表したVocabulary Learning via Optimal Transport for Neural Machine Translation (VOLT)という、自然言語処理の基本構成要素である“語彙”に着目した研究です。語彙のサイズを削減しながら、機械翻訳の精度を向上させることに成功しています。
(2)でご紹介したTransformerの事前学習モデルを利用して、機械翻訳を行う際にも、一丁目一番地に我々が行う必要があるのが、文章を特定の単位に区切る(トークナイズする)という処理です。このトークナイズをする基準となるのが、語彙ですが、本論文ではBERTやT5などで用いられているWordPiece/SentencePieceで区切るよりも少ない語彙で、高精度な機械翻訳を実現しています。
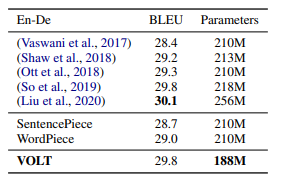
※Vocabulary Learning via Optimal Transport for Neural Machine Translationより引用
VOLTは、言語非依存で適用可能な手法であるため、日本語での活用も期待できます。ちなみに、日本国内で有名な形態素解析エンジンとしてはGoogleの工藤拓氏が開発されたMeCabや、京都大学黒橋研究室で開発されたJuman++、リクルートのAI研究機関Megagon Labsで最近バージョンアップされた「GiNZA ver.5」でも採用されているSudachiTraなどがあります。
